递归神经网络RNN(Recurrent Neural Network)
RNN简单介绍
关于RNN递归(循环)神经网络的知识点
以下内容用我自己理解的十分通俗的话描述出来,非常好理解
递归神经网络
意义
- 人工神经网络和卷积神经网络成立的前提假设是:元素之间是相互独立的,输入与输出也是独立的,那么对于元素或输入输出之间不独立(比如写一篇作文或画一幅画)的情况就无法处理,因此出现了递归神经网络,他的本质是:像人一样拥有记忆的能力
RNN结构
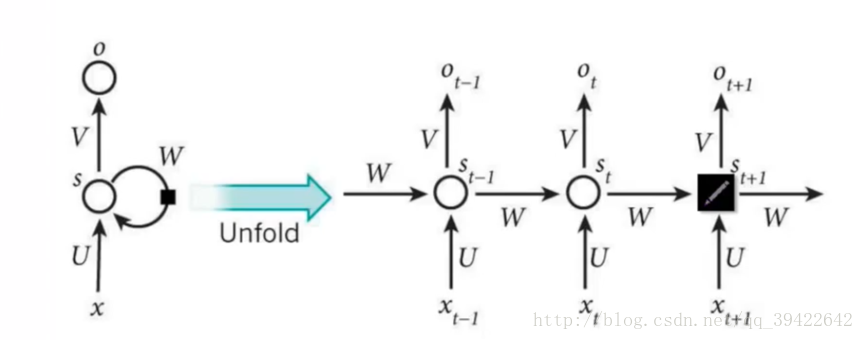
如上图所示,每个圆圈代表一个单元,$x、s、o$分别代表输入、记忆、输出,$U、V、W$代表权重,由于RNN具有记忆,因此在网络上的呈现就像多了一个时间的维度,并且RNN是一个$Sequence to Sequence$的模型,因此会出现
当前时刻的输出$Ot$是由当前时刻的输入$X_t$和记忆$S{t-1}$决定的
上式中的$f$为激活函数(RNN种常用的有$tanh$),用于过滤信息,因为有时候很久以前的记忆是没有作用的
于是最后一步就是预测了,如果是分类任务,那么通常情况下采用$softmax$函数来预测(不懂$softmax$的戳这里),记得带上权重矩阵
RNN的注意点:
- $O_t$是由当前时间以及之前所有的记忆得到的
- $S_t$捕捉之前时间点的信息,但不能捕捉之前所有时间点的信息
- $O_t$在很多情况下并不存在,因为大多数任务并不关注过程,只关注结果
RNN改进1:双向RNN
作用:能够同时利用过去和未来的信息
结构图:
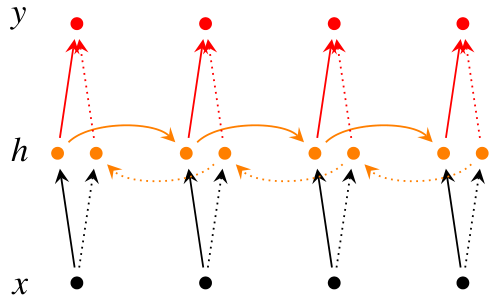
就像算法里的双向bfs一样,双向RNN的每个记忆节点同时利用过去的记忆和来自未来的记忆,因此所需内存是单向RNN的两倍
RNN改进2:深层双向RNN
改进:拥有多个隐含层
结构图:
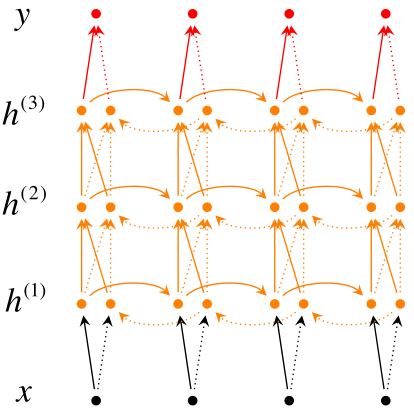
因此每个隐含层神经元的输入由两部分组成:
- 前一时刻的同一隐含层传来的信息
- 同一时刻上一个隐含层传来的信息(包括前向和后向)
最后利用最后一层来分类:
RNN的训练方式:BPTT(Back Propagation Through Time)
由之前分析可知,当前时刻的记忆:
利用该记忆通过$softmax$分类器输出概率:
接下来求出损失,这里使用交叉熵(crossentropy)损失函数:
把所有时刻的损失都加起来:
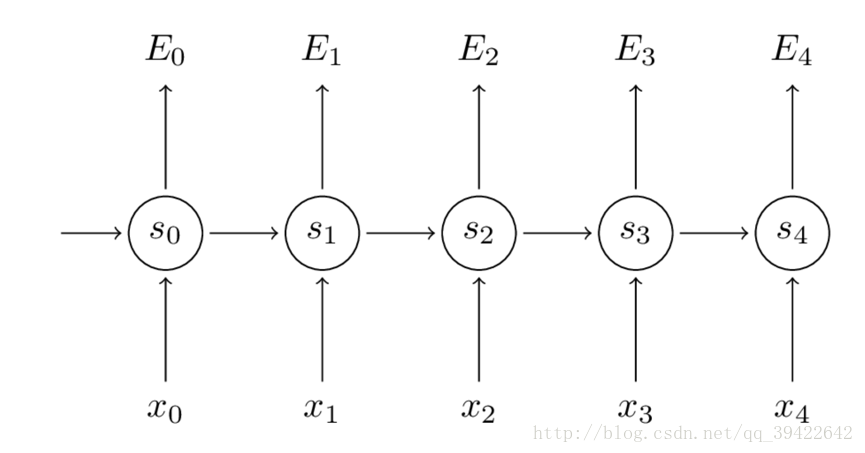
接下来就是根据损失函数利用SGD或者RMSprop之类的算法求解最优参数的过程了,在CNN和ANN里我们使用BP(反向传播)算法,利用链式求导法则完成这一过程的细节,但是对于RNN我们需要使用BPTT,区别也就是CNN和RNN的区别,它的输出不仅依赖于当前输入,还依赖于当前记忆,所以每个求导环节还要加上一个对前一时刻的的求导
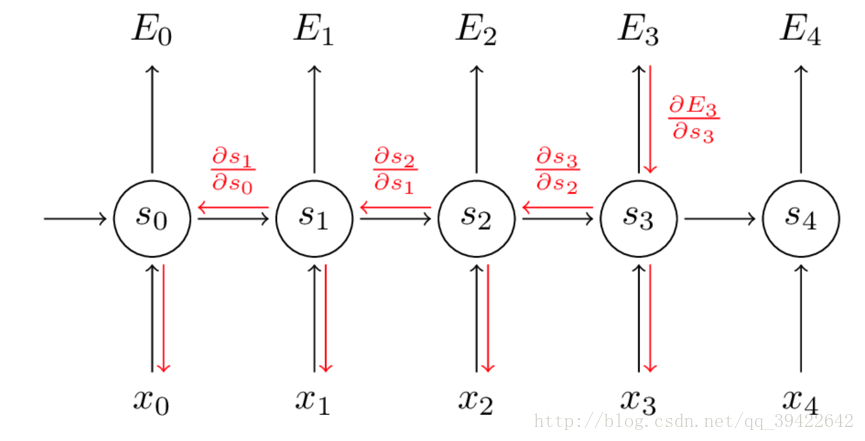
举个例子:让$E_3$对$W$求偏导,有如下公式
还没结束,我们发现
因此真正的求导过程长这样
可以看出,我们需要把当前时刻造成的损失和以往每个时刻造成的损失加起来,因此RNN设立了参数共享机制,这是CNN和ANN所没有的
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!